")
 Segunda parte de este análisis sobre tecnología emergente con nuevos modelos.
Segunda parte de este análisis sobre tecnología emergente con nuevos modelos.
Por Osvaldo Callegari*
Las aplicaciones de la Inteligencia Artificial se diversifican en diversas áreas y métodos de aplicación.
Dentro de las evaluaciones tecnológicas mostramos casos de estudios de productos como Azure de Microsoft y su Api de inteligencia para habilitar características de voz, visión y lenguaje.
Análisis de imágenes para obtener información
Es posible analizar imágenes para obtener datos precisos acerca de un objeto.
Actualmente algunos métodos están sufriendo prohibiciones, como es el caso de la ciudad de San Francisco que han impuesto una ley en la cual no está permitido hacer detecciones faciales.
Dicho esto vamos a las características de las librerías de aplicación:
• Etiquetar características visuales
◦ Identificar y etiquetar las características visuales de una imagen a partir de un conjunto de miles de objetos, seres vivos, paisajes y acciones reconocibles.
El etiquetado no se limita al sujeto principal, como una persona en primer plano, sino que también incluye el entorno (interior o exterior), muebles, herramientas, plantas, animales, accesorios, gadgets, etc.
• Detectar objetos
◦ La detección de objetos es similar al etiquetado, pero la API devuelve las coordenadas del rectángulo delimitador para cada etiqueta aplicada. Por ejemplo, si una imagen contiene un perro, un gato y una persona, la operación de detección mostrará esos objetos junto con sus coordenadas en la imagen.
• Detección de las marcas
◦ Identifica las marcas comerciales de imágenes o vídeos desde una base de datos de miles de logotipos globales. Puede usar esta característica, por ejemplo, para detectar qué marcas son más populares en medios sociales o más frecuentes en la ubicación de los productos multimedia.
• Clasificar una imagen
◦ Identificar y clasificar toda una imagen mediante una Taxonomía de Categorías
con jerarquías hereditarias de elementos primarios y secundarios.
▪ Las categorías se pueden usar solas o con nuestros nuevos modelos de etiquetado.
▪ Actualmente, el inglés es el único idioma que se admite para etiquetar y clasificar imágenes.
• Describir una imagen
◦ Generar una descripción de toda una imagen en lenguaje natural, con frases completas. Los algoritmos de Computer Visión (CV) generan varias descripciones en función de los objetos identificados en la imagen. Cada una de estas descripciones se evalúa y se genera una puntuación de confianza. Después, se devuelve una lista de puntuaciones de confianza ordenadas de más alta a más baja.
• Detectar caras
◦ Detectar caras en una imagen y proporcionar información acerca de ellas. Computer Vision devuelve las coordenadas, el rectángulo, el género y la edad de los rostros que detecta.
▪ A su vez proporciona un subconjunto de la funcionalidad que se puede encontrar en Face (Servicio Cognitivo) y este servicio se puede usar para obtener un análisis más detallado, como la identificación facial y la detección de posturas.
• Detectar tipos de imagen
◦ Detectar las características de una imagen, como por ejemplo, si una imagen es un dibujo lineal o la probabilidad de que sea una imagen prediseñada.
• Detectar contenido específico del dominio
◦ Usar los modelos de dominio para detectar e identificar el contenido específico del dominio en una imagen, como celebridades y monumentos. Por ejemplo, si una imagen contiene personas, Computer Vision puede usar un modelo de dominio para celebridades que se incluye con el servicio para determinar si las personas que se han detectado en la imagen coinciden con famosos conocidos.
• Detectar la combinación de colores
◦ Analizar el uso del color en una imagen. CV puede determinar si una imagen está en blanco y negro o en color, y en las imágenes de color, identificar los colores dominantes y de énfasis.
• Generar una miniatura
◦ Analizar el contenido de una imagen para generar una miniatura adecuada de la misma. En primer lugar, Computer Vision genera una miniatura de alta calidad después analizar los objetos de la imagen para determinar el área de interés. Computer Vision recorta la imagen para ajustarla a los requisitos del área de interés. La miniatura generada se puede presentar con una relación de aspecto diferente de la imagen original en función de sus necesidades.
• Obtener el área de interés
◦ Leer el contenido de una imagen para devolver las coordenadas del área de interés. Se trata de la misma función que se usa para generar una miniatura, pero en lugar de recortar la imagen, Computer Vision devuelve las coordenadas del rectángulo delimitador de la región, por lo que la aplicación que realiza la llamada puede modificar la imagen original según sea necesario.
Extracción de texto en las imágenes
Es posible utilizar Computer Vision para extraer el texto de una imagen en una secuencia de caracteres de lectura mecánica mediante el reconocimiento óptico de caracteres (OCR).
Si es necesario, OCR corrige el giro del texto reconocido y proporciona las coordenadas del marco de cada palabra. El OCR admite 25 idiomas y detecta automáticamente el idioma del texto reconocido.
También puede usar Read API para extraer texto impreso y manuscrito de imágenes y documentos con mucho texto. Read API utiliza modelos actualizados y sirve para diferentes objetos con superficies y fondos distintos, como recibos, pósteres, tarjetas de visita, cartas y pizarras. Actualmente, Read API se encuentra disponible en versión preliminar y en inglés, ya que se trata del único idioma compatible.
Moderación del contenido de las imágenes
Es posible usar VC para detectar contenido para adultos y subido de tono en una imagen y devolver una puntuación de confianza para ambos.
Uso de contenedores Docker
Use contenedores de Computer Vision para reconocer texto impreso y manuscrito localmente, mediante la instalación de un contenedor de Docker estándar más cercano a los datos.
Requisitos de imagen
Computer Vision puede analizar las imágenes que cumplan los requisitos siguientes:
• La imagen se debe presentar en formato JPEG, PNG, GIF o BMP
• El tamaño de archivo de la imagen debe ser inferior a 4 megabytes (MB)
• Las dimensiones de la imagen deben ser mayores que 50 x 50 píxeles
• Para OCR, el tamaño de la imagen de entrada debe estar entre 50 x 50 y 4200 x 4200 píxeles.
Seguridad y privacidad de los datos
Al igual que sucede con todas las instancias de Cognitive Services, los desarrolladores que usan el servicio Computer Vision deben estar al tanto de las directivas de Microsoft sobre los datos de clientes. Para más información, consulte la página de Cognitive Services en Microsoft Trust Center.
Ingeniería de la Información
Muchos incluyen a la Visión Computacional dentro de la ingeniería de la información.
La ingeniería de la información comprende los siguientes campos:
• Aprendizaje automático
• Inteligencia artificial
• Teoría del control
• Procesamiento de señales
• Teorías de la información
• Visión computacional
• Imágenes médicas
• Quimioinformática
• Robótica autónoma
• Robótica móvil
• Telecomunicaciones
Muchas de las áreas se originan en las ciencias de la computación.

Figura 1. Gráfico de áreas con su cercanía.
Una parte importante de la inteligencia artificial tiene que ver con la planificación o la deliberación de un sistema que puede realizar acciones mecánicas, como mover un robot a través de algún entorno.
Este tipo de procesamiento normalmente necesita datos de entrada proporcionados por un sistema de visión por computadora, que actúa como un sensor de visión y proporciona información de alto nivel sobre el entorno y el robot.
Otras partes que a veces se describen como pertenecientes a la inteligencia artificial y que se usan en relación con la visión por computadora son el reconocimiento de patrones y las técnicas de aprendizaje.
Investigadores de la Universidad Estatal de Carolina del Norte han desarrollado una nueva técnica que mejora la capacidad de las tecnologías de visión artificial para identificar y separar mejor los objetos en una imagen, un proceso denominado segmentación.
El procesamiento de imágenes y la visión por computadora son importantes para múltiples aplicaciones, desde vehículos autónomos hasta la detección de anomalías en las imágenes médicas.
Las tecnologías de visión artificial utilizan algoritmos para segmentar, o delinear los objetos, en una imagen. Por ejemplo, separar el contorno de un peatón en el contexto de una calle concurrida.
Estos algoritmos se basan en parámetros definidos, valores programados, para segmentar imágenes. Por ejemplo, si hay un cambio en el color que cruza un umbral específico, un programa de visión por computadora lo interpretará como una línea divisoria entre dos objetos. Y ese umbral específico es uno de los parámetros del algoritmo.
Pero hay un reto aquí. Incluso pequeños cambios en un parámetro pueden llevar a resultados de visión de computadora muy diferentes. Por ejemplo, si una persona que cruza la calle entra y sale de áreas con sombra, eso afectaría el color que ve una computadora, y la computadora puede "ver" a la persona que desaparece y reaparece, o interpretar a la persona y la sombra como un objeto único, grande como un coche.
"Algunos parámetros de algoritmos pueden funcionar mejor que otros en cualquier conjunto de circunstancias, y queríamos saber cómo combinar múltiples parámetros y algoritmos para crear una mejor segmentación de imágenes mediante programas de visión por computadora", dice Edgar Lobatón, profesor asistente de electricidad y computadoras. Ingeniería en NC State y autor principal de un artículo sobre el trabajo.
Lobatón y el estudiante Qian Ge desarrollaron una técnica que compila datos de segmentación de múltiples algoritmos y los agrega, creando una nueva versión de la imagen. Esta nueva imagen se segmenta nuevamente, según la persistencia de un segmento dado en todos los algoritmos de entrada originales.
"Visualmente, los resultados de esta técnica se ven mejor que cualquier algoritmo dado por sí solo", dice Lobatón. "Sin embargo, la naturaleza de este trabajo no se alinea con las métricas existentes para medir la precisión de la visión de la computadora. Por lo tanto, necesitamos desarrollar un nuevo medio para evaluar la precisión de la visión de la computadora: ese es un proyecto futuro para nosotros".
Lobatón señala que la nueva técnica de segmentación de imágenes se puede utilizar en tiempo real, procesando 30 cuadros por segundo. Esto se debe, en parte, al hecho de que la mayoría de los pasos computacionales se pueden ejecutar en paralelo, en lugar de secuencialmente.
El documento, "Segmentación de la imagen basada en el consenso a través de la persistencia topológica", se presentará el 1 de julio en la Conferencia IEEE sobre visión por computadora y reconocimiento de patrones en Las Vegas, Nevada.
Fuente de la historia
Materiales proporcionados por North Carolina State University . Nota: El contenido puede ser editado por estilo y longitud.
En nuestro artículo la visión computacional podemos decir que es el campo que trata de lograr que las computadoras comprendan los datos de imagen y video a un alto nivel.
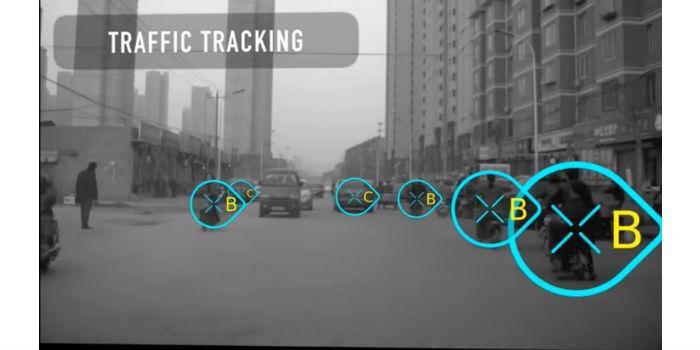
Ejemplo en Youtube de interacciones de CogniMem Technologies (r)
Ejemplo de Visión Computacional de Sef Vision
Los nombres y marcas mencionadas son nombres y marcas registradas de sus propietarios. Fuentes de Consultas: Microsoft Corp a través de su Agencia Salem Viale. Wikipedia y su información de common License y Sans. Org. Las fuentes pueden variar en distintos autores y ensayos vertidos.
* Para comunicarse con el autor de este artículo escriba a [email protected]























Deje su comentario